Imagine this: it’s 3 a.m., a breaking story hits your Telegram channel, and within minutes, the comment section explodes. Half the messages are insightful questions from loyal readers. The other half? Spam bots, angry trolls, and accidental misinformation. If you’re managing this manually, you’re already losing. But if you let an untrained Large Language Model (LLM) is an advanced artificial intelligence system capable of understanding, generating, and analyzing human language with high contextual accuracy. run wild, you risk banning innocent users or letting harmful content slip through.
The sweet spot isn’t choosing between humans and machines. It’s building a hybrid workflow where Telegram Bots act as automated software applications that interact with users via the Telegram messaging platform using APIs. handle the heavy lifting, LLMs provide nuanced judgment, and your team makes the final call. This guide breaks down exactly how to build that system in 2026, avoiding common pitfalls like misclassifying counterspeech or drowning in false positives.
Why Traditional Filters Fail in News Channels
If you’ve ever used keyword-based filters, you know they’re blunt instruments. Block the word "kill," and you block news about a movie review. Block political slurs, and you might accidentally silence legitimate reporting on hate crimes. Legacy linear classifiers struggle with context, sarcasm, and evolving slang.
LLMs change the game because they understand intent, not just patterns. According to research summarized by Tech Policy Press, modern generative models can increase detection accuracy for subtle violations like harassment or dog-whistle politics by double-digit percentages compared to older methods. They can also explain *why* they flagged something, which is crucial when you need to justify a ban to a user or audit your own team’s decisions.
However, there’s a catch. Studies show that even top-tier commercial LLMs misclassify "counterspeech"-where users argue against hate speech-as actual hate speech in 15-20% of cases. In a news context, quoting a controversial figure to critique them is standard practice. An automated system that deletes those quotes destroys your credibility. That’s why full automation is dangerous; a human-in-the-loop design is non-negotiable for serious newsrooms.
Architecting Your Moderation Pipeline
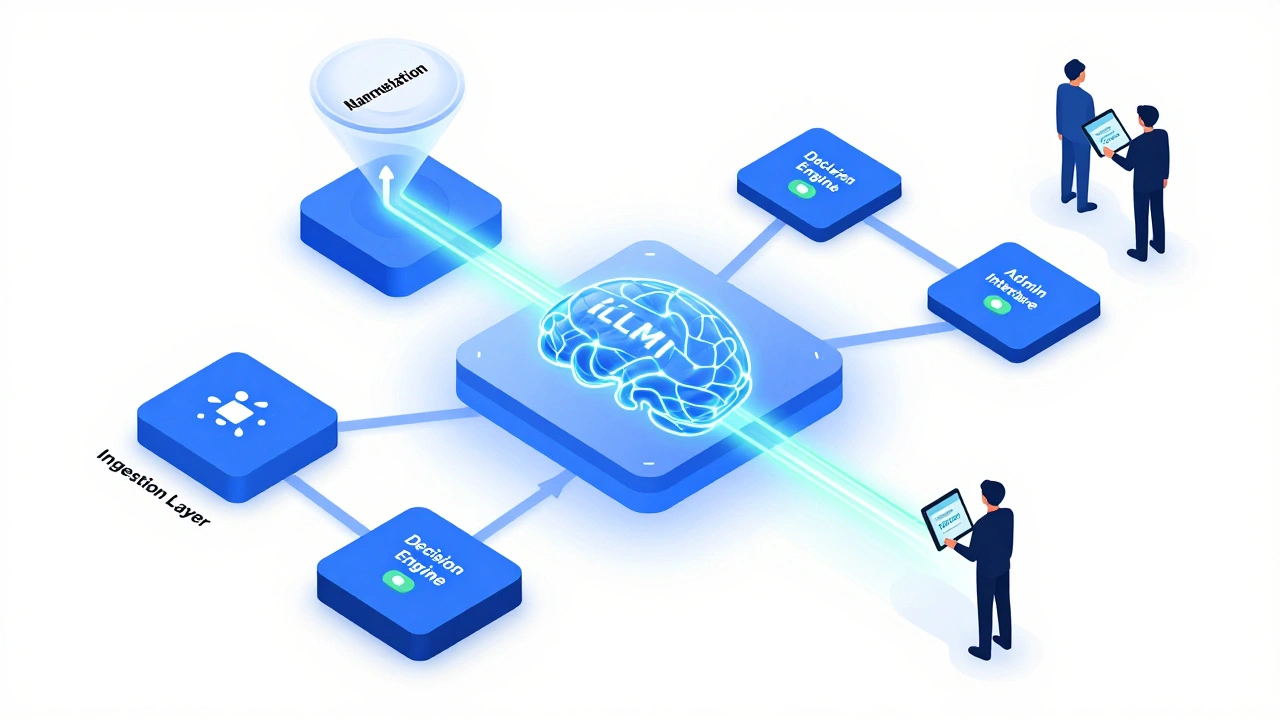
You don’t need to rebuild the internet to get started. A robust integration typically involves five core components working together:
- The Ingestion Layer: This collects candidate content. For news posts, this might be RSS feeds pulled via tools like n8n is a fair-code workflow automation tool that allows users to connect various apps and services without coding.. For comments, it’s the Telegram Bot API listening for updates.
- The Normalization Step: Before sending data to an AI, clean it up. Detect the language, strip HTML tags, and anonymize sensitive metadata if privacy is a concern.
- The LLM Service: This is your brain. You can use hosted APIs like Google’s Gemini or self-host open-source models like Llama-3. The model receives the text and your policy rules, then returns labels, confidence scores, and explanations.
- The Decision Engine: This logic layer interprets the LLM’s output. If confidence > 90% for "spam," auto-delete. If confidence is 60% for "misinformation," flag for human review.
- The Admin Interface: Where humans live. In Telegram, this is often a private chat with inline buttons (Approve, Reject, Escalate) so moderators never leave the app.
For production environments handling thousands of messages per hour, avoid long polling. Use webhooks to push updates to your backend instantly. Latency matters-if a moderator has to wait 10 seconds for a decision, the workflow breaks.
Designing Policies That Actually Work
Your LLM is only as good as your prompts. You can’t just say "moderate this." You need a structured policy schema. Start by decomposing your Trust and Safety guidelines into specific categories:
- Hate Speech
- Harassment
- Misinformation/Disinformation
- Adult Content
- Spam/Self-Promotion
Create prompt templates that define each category clearly. Include positive examples (what gets banned) and negative examples (what stays). Ask the model to output machine-readable JSON with fields for `label`, `confidence_score`, and `rationale`.
Here’s a critical tip from Musubi Labs’ implementation guides: measure precision, recall, and F1 score at the category level before going live. Run offline tests on historical data. If your model flags 50% of legitimate political debate as "toxicity," your precision is too low. Adjust your thresholds or refine your definitions until you hit target metrics-ideally above 0.9 precision for high-risk categories like illegal content.
Building the Human-in-the-Loop Workflow
Automation should assist, not replace. Here’s how to structure the interaction between your bot and your editors:
When a new message arrives, the bot sends it to the LLM service. The service returns a verdict. If the verdict is "Safe," the message posts immediately. If it’s "High Risk," the bot hides the message and sends an alert to your private moderation channel.
In that private channel, the editor sees:
- The original message
- The LLM’s suggested action (e.g., Delete)
- The LLM’s explanation (e.g., "Contains targeted harassment based on ethnicity")
- Inline buttons: [Approve Deletion] [Allow Post] [Escalate]
This pattern mirrors successful workflows seen in n8n templates for AI news curation, where a human must tap "Approve" before a draft goes public. By keeping humans in control of final decisions, you maintain trust with your audience. Users may distrust fully automated bans, but they respect transparent, human-reviewed processes. Plus, every time an editor overrides the LLM, you generate training data to improve the model over time.
Performance, Cost, and Scaling Considerations
LLMs are computationally expensive. Running a model on every single comment in a viral thread can spike costs quickly. To manage this:
Use Tiered Processing: Don’t send everything to the big, expensive model. Use a lightweight classifier first to filter out obvious spam or safe content. Only route ambiguous or high-stakes messages to the LLM. This reduces load by up to 70% in many scenarios.
Batching and Caching: If you’re processing similar messages (e.g., replies to the same post), batch them. Cache responses for identical inputs. For breaking news events where volume spikes, decouple ingestion from decision-making using message queues like RabbitMQ or Kafka. This ensures your bot doesn’t crash under pressure.
Model Choice: Hosted APIs like Gemini offer ease of use but charge per token. Open-source models like Llama-3 allow self-hosting, giving you better cost control and data privacy. For newsrooms handling whistleblower tips or sensitive sources, self-hosting is often mandatory to prevent third-party data leakage.
| Feature | Keyword Filters | Traditional ML Classifiers | LLM-Assisted (Human-in-Loop) |
|---|---|---|---|
| Context Understanding | Poor | Moderate | High |
| Adaptability to Slang/New Threats | Low (Manual Updates) | Medium (Retraining Needed) | High (Prompt Tuning) |
| Explainability | None | Limited | Detailed Rationales |
| Cost at Scale | Very Low | Low | High (Mitigated by Tiering) |
| Risk of False Positives | High | Medium | Low (With Human Review) |

Compliance and Ethical Guardrails
Integrating AI into moderation brings legal and ethical responsibilities. Under regulations like the EU’s Digital Services Act, platforms must demonstrate transparency and accountability.
Audit Logs Are Mandatory: Log every decision. Store the input text, the LLM’s output, the confidence score, the model version, and the final human action. This allows you to retrospectively audit cases, retrain prompts if bias is detected, or roll back updates if behavior changes unexpectedly.
Privacy First: Minimize data retention. Don’t store raw user messages longer than necessary. Encrypt any stored logs. If you’re using third-party APIs, ensure their terms comply with your region’s data protection laws. For highly sensitive news operations, consider local deployment of open-source models to keep data entirely within your infrastructure.
Fairness Audits: LLMs can inherit biases from their training data. Regularly test your system across different dialects, languages, and political viewpoints. If your model is systematically harsher on certain groups, adjust your policies and retrain. Transparency builds trust-publish your moderation guidelines and escalation channels publicly.
Getting Started: A Practical Roadmap
You don’t need to boil the ocean. Start small:
- Week 1-2: Proof of Concept. Connect one Telegram channel to a simple pipeline. Use a tool like n8n to aggregate RSS feeds, summarize them with an LLM, and post drafts to a private chat for approval. Limit scope to one language and three moderation categories.
- Week 3-4: Policy Refinement. Externalize your policy configuration. Build a basic admin interface with inline buttons. Collect feedback from 3-5 editors on false positives/negatives.
- Week 5-6: Offline Evaluation. Run historical data through your LLM. Compare results against past human decisions. Calculate precision and recall. Tune your prompts until metrics meet your targets.
- Week 7+: Gradual Rollout. Expand to more channels. Introduce tiered processing to manage costs. Monitor latency and error rates closely. Keep humans in the loop for all borderline cases.
By mid-2026, hybrid human-AI moderation is becoming the default for serious news publishers. The technology is mature enough to be useful, but fragile enough to require careful stewardship. Treat your LLM as a powerful intern-fast, smart, but prone to mistakes. Supervise it closely, give it clear instructions, and always keep the final say in human hands.
Which LLM is best for Telegram moderation?
There is no single "best" model. Commercial APIs like Google Gemini or OpenAI’s GPT-4 offer high accuracy and ease of integration but raise privacy concerns due to data transmission. Open-source models like Llama-3 allow self-hosting, providing better data control and cost predictability for high-volume channels. Choose based on your privacy requirements, budget, and technical capacity for maintenance.
Can I fully automate moderation with an LLM?
It is strongly advised against full automation for news contexts. Research indicates significant risks in misclassifying counterspeech and nuanced political discourse. A human-in-the-loop approach, where the LLM flags content and humans make final decisions, balances efficiency with safety and maintains audience trust.
How do I handle high traffic volumes without high costs?
Implement tiered processing. Use lightweight, cheap classifiers to filter obvious spam or safe content. Only route ambiguous or high-risk messages to the expensive LLM. Additionally, use caching for repeated inputs and batch processing for similar messages to reduce API calls.
What data should I log for compliance?
Log the input text, LLM output (labels, scores, rationale), model version, timestamp, and the final human action taken. Ensure these logs are encrypted and retained according to your jurisdiction’s data protection laws (e.g., GDPR or DSA). Avoid storing unnecessary personal data beyond what is needed for moderation audits.
How do I mitigate bias in my moderation model?
Regularly audit your model’s performance across different demographics, dialects, and political viewpoints. Use diverse training data and test sets. Implement fairness checks to detect systematic disparities in flagging rates. Continuously refine your prompt engineering to clarify edge cases and reduce ambiguity.
Latest Posts